Open Table Format
Table formats are a way to organize data files, they try to bring database-like features to data lake. Apache Hive is one of the earliest and most used table formats, but it was not written for object storage like AWS S3 or Alibaba OSS, rapid growing metadata tables slow down its performance. Newer systems like Apache Iceberg, Apache Hudi and Delta lake try to solve the problem as well as bringing the following features to the data lake:

Apache Iceberg
Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
Iceberg is designed to improve the known scalability limitations of Hive, which stores table metadata in a metastore that is backed by a relational database such as MySQL.
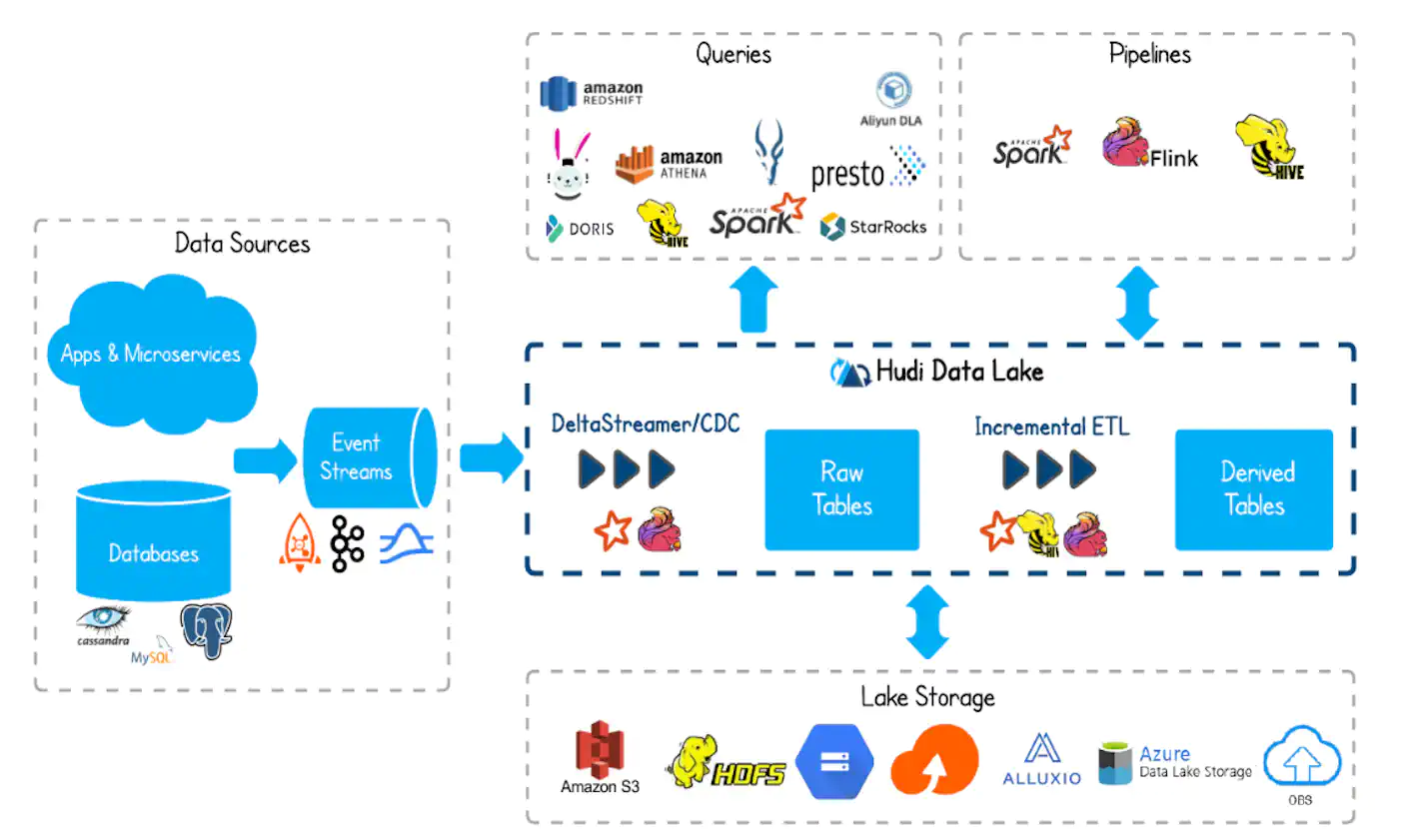
Apache Hudi
Hudi brings transactions, record-level updates/deletes and change streams to data lakes!
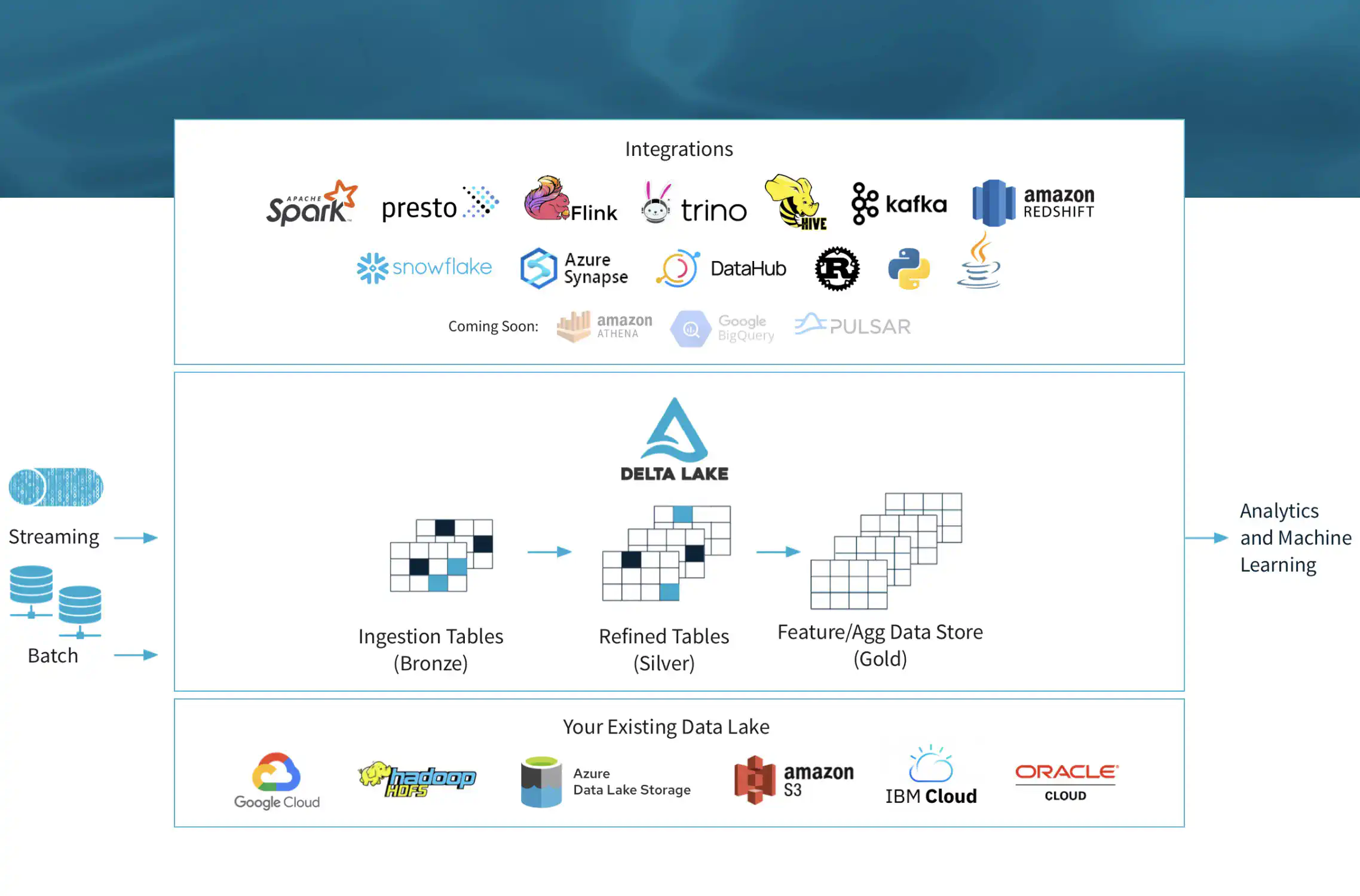
Delta Lake
Delta Lake is an open-source storage framework that enables building a Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, and Hive and APIs for Scala, Java, Rust, Ruby, and Python.
Recent posts

Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for compute engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
OpenTableFormat

OpenTableFormat is to object storage what constellation is to stars.
OpenTableFormat

OpenTableFormat