A little bit of Apache Iceberg

Apache Iceberg1 is an open table format for huge analytic datasets, it brings the reliability and simplicity of SQL tables to big data, while making it possible for compute engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
A table format helps you manage, organize, and track all of the files that make up a table, this enable database-like semantics over files; you can easily get features such as ACID compliance, time travel, and schema evolution, making your files much more useful for analytical queries. Iceberg is one of many solutions to implement a table format over sets of files; with table formats the headaches of working with files can disappear. Iceberg was created by Netflix and later donated to the Apache Software Foundation.
What Iceberg is and what it isn’t:
| ✅ What Iceberg is | ❌ What Iceberg is not |
|---|---|
| A table format specification | A storage engine or execution engine |
| A set of APIs and libraries for engines to interact with tables following that specification | A service |
Basic Concepts
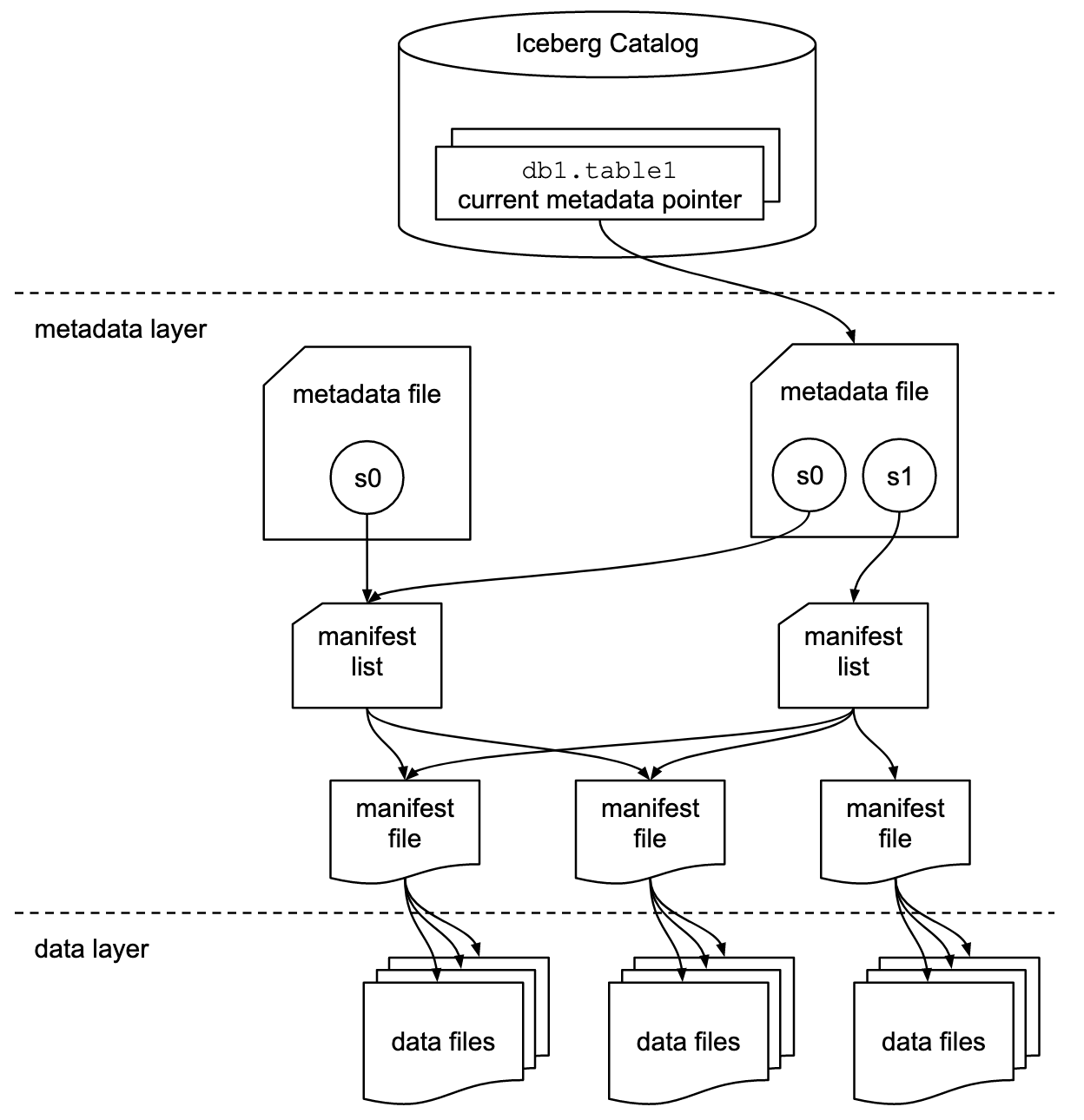
The Iceberg table’s architecture consist of three layers:
- Iceberg catalog: The catalog is where services go to find the location of the current metadata pointer, which helps identify where to read or write data for a given table. Here is where references or pointers exist for each table that identify each table’s current metadata file.
- Metadata layer: This layer consists of three components:
metadata file,manifest list, andmanifest file.- The metadata file includes information about a table’s schema, partition information, snapshots, and the current snapshot.
- The manifest list contains a list of manifest files, along with information about the manifest files that make up a snapshot.
- The manifest files track data files in addition to other details and statistics about each file.
- Data layer: Each manifest file tracks a subset of data files, which contain details about partition membership, record count, and lower- and upper-bounds of columns.
After INSERT some data and do a COMMIT, the following process happens:
- The data in the form of a Parquet file is first created
- Then, a manifest file pointing to this data file is created (including the additional details and statistics)
- Then, a manifest list pointing to this manifest file is created (including the additional details and statistics)
- Then, a new metadata file is created based on the previously current metadata file with a new snapshot as well as keeping track of the previous snapshots, pointing to this manifest list (including the additional details and statistics)
- Then, the value of the current metadata pointer for the table is atomically updated in the catalog now point to this new metadata file
During all of these steps, anyone reading the table would continue to read the first metadata file until the atomic step #5 is complete, meaning that no one using the data would ever see an inconsistent view of the table’s state and contents.
When SELECT is executed, the following process happens:
- The query engine goes to the Iceberg catalog
- It then retrieves the current metadata file location entry for the table
- It then opens this metadata file and retrieves the entry for the manifest list location for the current snapshot
- It then opens this manifest list, retrieving the location of the manifest files
- It then opens this manifest files, retrieving the location of data files
- It then reads these data files
Step #3 can prune some partitions based on the partition specification, step #5 can filter some data file base on the statistics.
Another key capability the Iceberg table format enables is something called “time travel”, using the following syntax to retrive the snapshot and use the snapshot to query the table futher.
SELECT * FROM table1 AS OF '2021-01-28 00:00:00';
A detailed demo can be seen here.
Supported Engines
Spark is currently the most well-supported compute engine for Iceberg operations, and lots of other compute engines are making efforts to support this promising table format.
| Engine | Supported Operations2 | Description |
|---|---|---|
| Spark | Read + Write | Iceberg uses Apache Spark’s DataSourceV2 API3 for data source and catalog implementations. |
| Flink | Read + Write | Iceberg supports both Apache Flink’s DataStream API and Table API4. |
| Hive | Read + Write | Iceberg supports reading and writing Iceberg tables through Hive by using a StorageHandler5. |
| Trino | Read + Write | Using Iceberg connector6 to read and write the supported data file formats Avro, ORC, and Parquet, following the Iceberg specification. |
| Presto | Read + Write | Using Iceberg connector7 to query and write Iceberg tables. |
| Dremio | Read + Write | Dremio integrated support for Iceberg tables to leverage powerful SQL database-like functionality through industry standard methods for data lakes8. |
| StarRocks | Read | From v2.1.0, StarRocks provides external tables to query data in Apache Iceberg9. |
| Athena | Read + Write | AWS Athena supports read, time travel, write, and DDL queries for Apache Iceberg tables10 that use the Apache Parquet format for data and the AWS Glue catalog for their metastore. |
| Impala | Read + Write | Currently only Iceberg V1 DML operations are allowed11, i.e. INSERT INTO /INSERT OVERWRITE. Iceberg V2 operations like row-level modifications (UPDATE, DELETE) are not supported yet. |
| Doris | Read | Iceberg External Table of Doris12 provides Doris with the ability to access Iceberg external tables directly. |
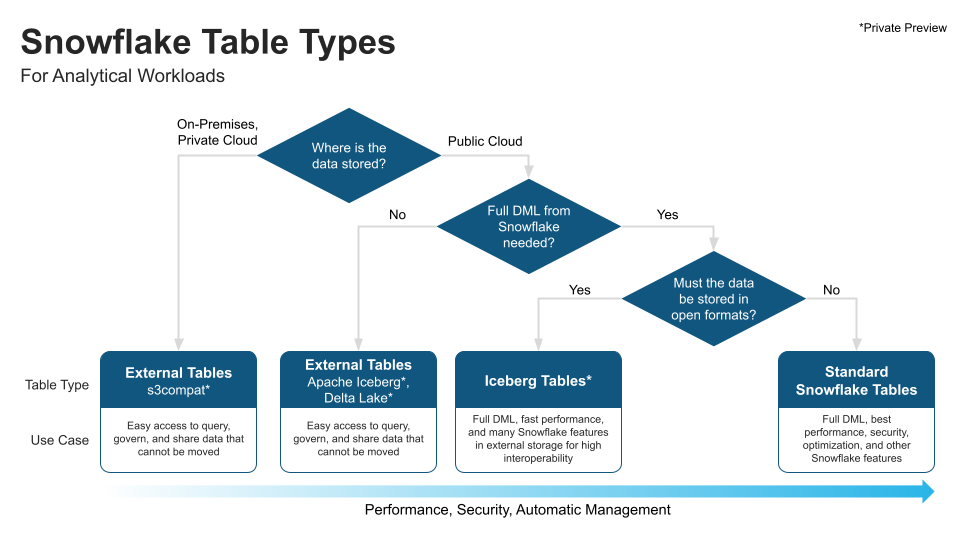
| Snowflake | Read + Write | With Iceberg Tables, our goal is to get as close to Snowflake native tables as possible, without breaking open source compatibility. |
Snowflake supports Iceberg External Tables as well as Iceberg Tables13, you can think of Iceberg Tables as Snowflake tables that use open formats and customer-supplied cloud storage. Snowflake provides a flow chart on how to choose different table types:
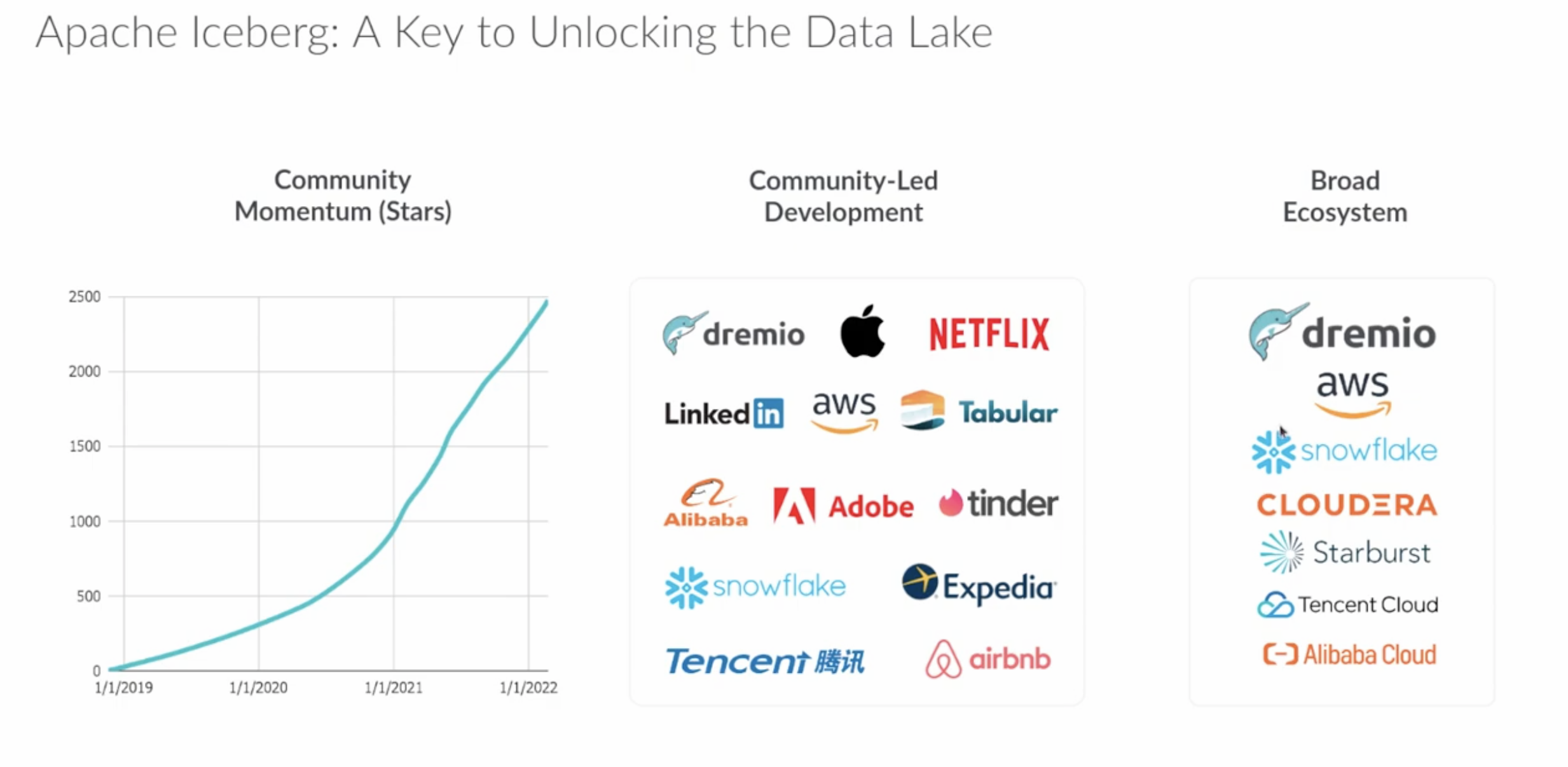
Involved Vendors
- Cloudera
- Dremio
- Snowflake
- Starburst
- Tabular
- Nexflex
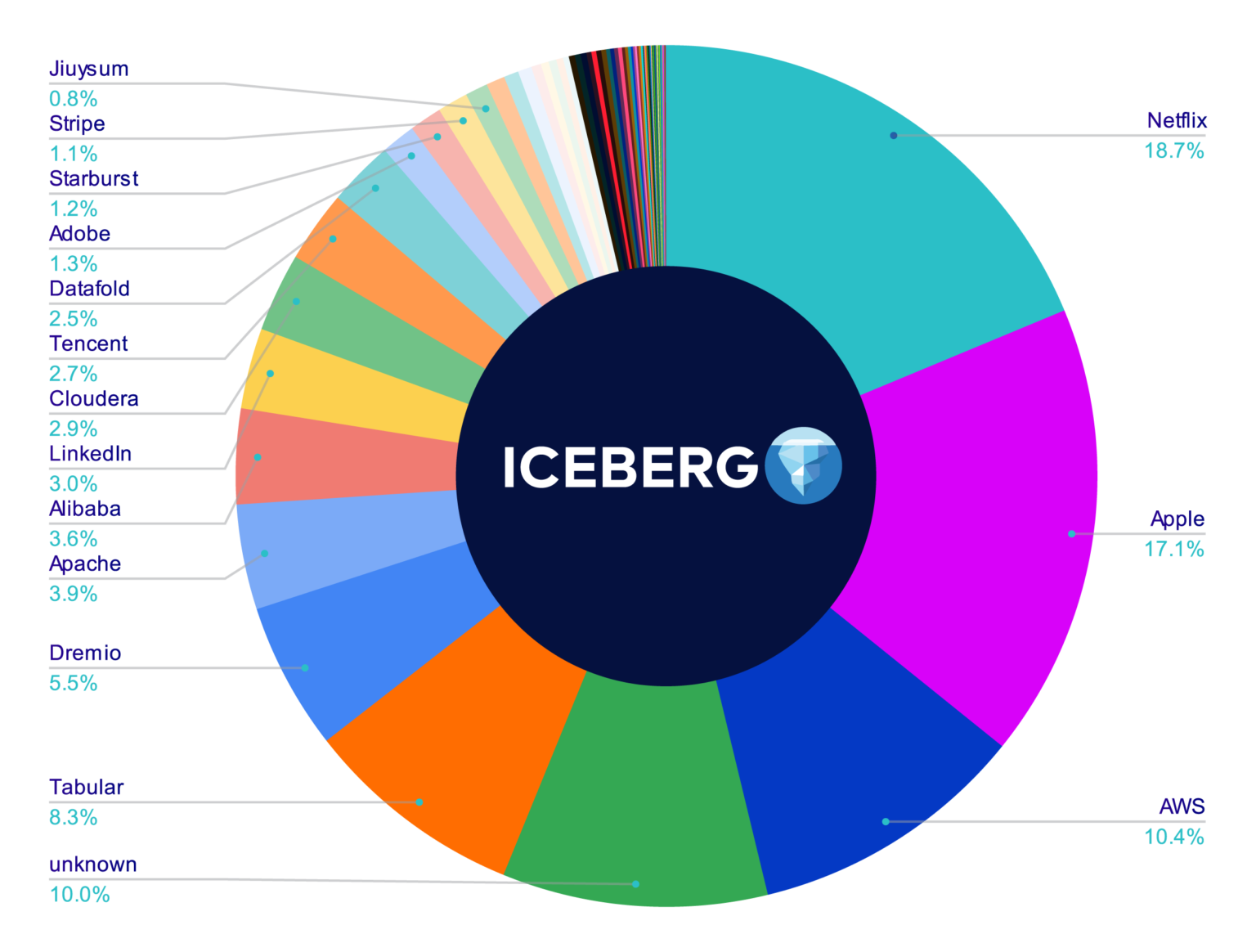
Diversity of Contributions by Company (Until April 2022)
References:
[1] Iceberg Table Spec
[2] Apache Iceberg: An Architectural Look Under the Covers by Jason Hughes
[3] Expanding the Data Cloud with Apache Iceberg by James Malone, Jan 2022
[4] 5 Compelling Reasons to Choose Apache Iceberg by James Malone, Jul 2022
[5] Iceberg Tables: Powering Open Standards with Snowflake Innovations by James Malone, Aug 2022
[6] What Are Iceberg Tables In Snowflake? 6 Minute Demo
[7] Iceberg: a fast table format for S3 by Ryan Blue, Jun 2018
[8] Apache Iceberg - A Table Format for Huge Analytic Datasets by Ryan Blue, Nov 2019
[9] Data architecture in 2022 by Ryan Blue, May 2022
[10] Apache Iceberg 101 from Dremio, Sep 2022
[11] Using Apache Iceberg for Multi-Function Analytics in the Cloud by Bill Zhang, Mar 2022
[12] Apache Iceberg - An Architectural Look Under the Covers by Jason Hughes, Nov 2021